Rclone and Go

This is a transcript of a talk I gave at the Go London User Group on 2018-11-21. You can watch it on YouTube (26 minutes) or see the slides and read the words here.
It's about rclone and how rclone uses the Go programming language.
Introduction

Good evening.
I’m Nick Craig-Wood and I’m here to talk about rclone. Rclone is an Open Source command line program to transfer files to and from cloud storage started by me as a hobby in 2012.
First a bit about me. I’ve loved programming ever since I was 13 with my ZX80 and have been doing it ever since.
Now-a-days I’m CTO of Memset Ltd who do cloud hosting and storage. I don’t get the chance to do a lot of coding at work any more so I now do Open Source coding as a hobby.
I’ve always had a keen interest in storing data, keeping it safe and transferring it about – hence rclone which is an embodiment of those things!
I used to be a data hoarder, but the house filled up with servers and disks and my wife complained about the electricity bill so I’m mostly reformed now.
Thank heavens for cloud storage!

My talk this evening is going to start with a quick summary of rclone and its history.
I’ll dive into how it works, and show a bit of code.
I’ll then discuss how you test a project like rclone and round off with a look at some of my favourite libraries.
But before I get going I don’t want you to get the impression rclone is all my work. I’d like to thank my excellent core developers, the super helpful group of people on the forum and anyone who has sent a PR or raised an issue – rclone wouldn’t be what it is today without you.. Oh and thank you for everyone who has sent a PR correcting my spelling :-)
What is rclone?

In summary rclone is a command line program to sync your data to and from cloud providers.
Rclone takes lots of care with data integrity, checking hashes at every step and preserves timestamps on your files.
It can transfer data directly between cloud providers so you can use it to back up your s3 objects to google cloud storage.
It has some optional features like encryption, but by and large rclone maps objects 1:1 from source to destination.
There is lots more info on the website.

Many of you will be familiar with rsync. Which is (see slide)
Rclone syncing works very much like rsync. I’ve tried to keep the flags the same where possible to make it familiar to rsync users.
There is one thing rclone does not do though and that is implement the extremely clever delta encoding that rsync uses for transferring objects.
That unfortunately isn’t possible when trying to copy objects 1:1 to cloud providers as they just don’t provide the API to do it.
It would be possible to implement it but you’d lose that 1:1 mapping of objects.

Rclone supports most major cloud providers. Well I think so, they keep making new ones!
Certainly all the big names are here, both for business use like s3, google cloud storage, azure blob storage and for personal like google drive and dropbox.
There are also the standard protocols like FTP, SFTP, HTTP.
I particularly like the HTTP backend – you point it file listing webpage (for example the ones apache generates) and it can pull the files off there recursively, or you can mount it as a disk.
All rclone operations are supported by all providers.

Thanks to Go’s amazing cross compiling abilities, rclone runs on nearly every platform you can think of.
Rclone is licenced under a very liberal MIT licence which means that it gets bundled into Synology NAS and other products like that.
Nearly all the platforms are cross compiled on a linux host as part of the Travis build. All except Windows and macOS which I had to build natively to fix various problems.

As I began to do less programming at work, I realised I needed to do some programming at home in order to retain my sanity.
In 2012 I decided to learn Go as it had just reached the exciting milestone of a 1.0 release.
I made a few test programs then I wrote my first major go library, an interface for the openstack swift object storage system.
I need a program to exercise that “swiftsync” which became “rclone”.

There were some things that attracted me immediately to Go.
We’d been using Python a lot at work so the single binary for a deployment was just breath of fresh air.
Go excels in concurrency which is really important for rclone too. Everything works concurrently in rclone such as directory listings and transfers of objects.
I started using Go as a new challenge and it has really brought back the joy of programming for me personally.
Lastly Go is a really easy language to pick up, especially if you’ve done any programming in a language similar to C such as Java.

From its humble beginnings rclone has grown into quite a large project.
As of today we’ve got about 11,000 stars on github, 200 contributors who’ve made 500 pull requests. Rclone get’s downloaded quarter of a million times a month and it has been packaged by the major Linux, Windows and Mac distributions.
Exactly how rclone got all those users is a mystery, but being on the front page of Hacker news added about 1,000 github stars overnight. Unfortunately at that time I was in the Outer Hebrides with no Internet so I had no idea this was happening!
Here is a visualisation of rclone’s source code made with Gource.
Rclone was created in 2012 and it got off to a slow start with just me – that is me whizzing about.
Rclone reached v1.00 in 2014 and supported 3 backends: s3, drive and swift.
Rclone gained its first external contribution in 2015. That was when it implemented Amazon Drive and it started to get popular.
In 2016 it gained some traditional protocols, SFTP and FTP and by 2017 I’d finally figured out I needed a VFS layer. Which brings us to the frenzy of 2018!

In 2017 I was surprised to find rclone in the middle of a minor media storm.
This is how...In 2015 Amazon launched their Unlimited Drive Storage product.
This, for a certain kind of person that you can find on the data hoarders subreddit was a personal challenge as you can imagine.
The screenshot on the left was sent to me from that reddit and all the data (1 Peta byte of it) was uploaded with rclone.
Rclone was banned from Amazon Cloud Drive, probably as a consequence of this, though ostensibly it was the use of encrypted keys within the binary. Amazon also shut down the unlimited Drive product in the US
I was surprised to have an interview with a journalist from The Register.
Rclone is still banned from Amazon Cloud Drive unless you have your own keys.
How does it work?
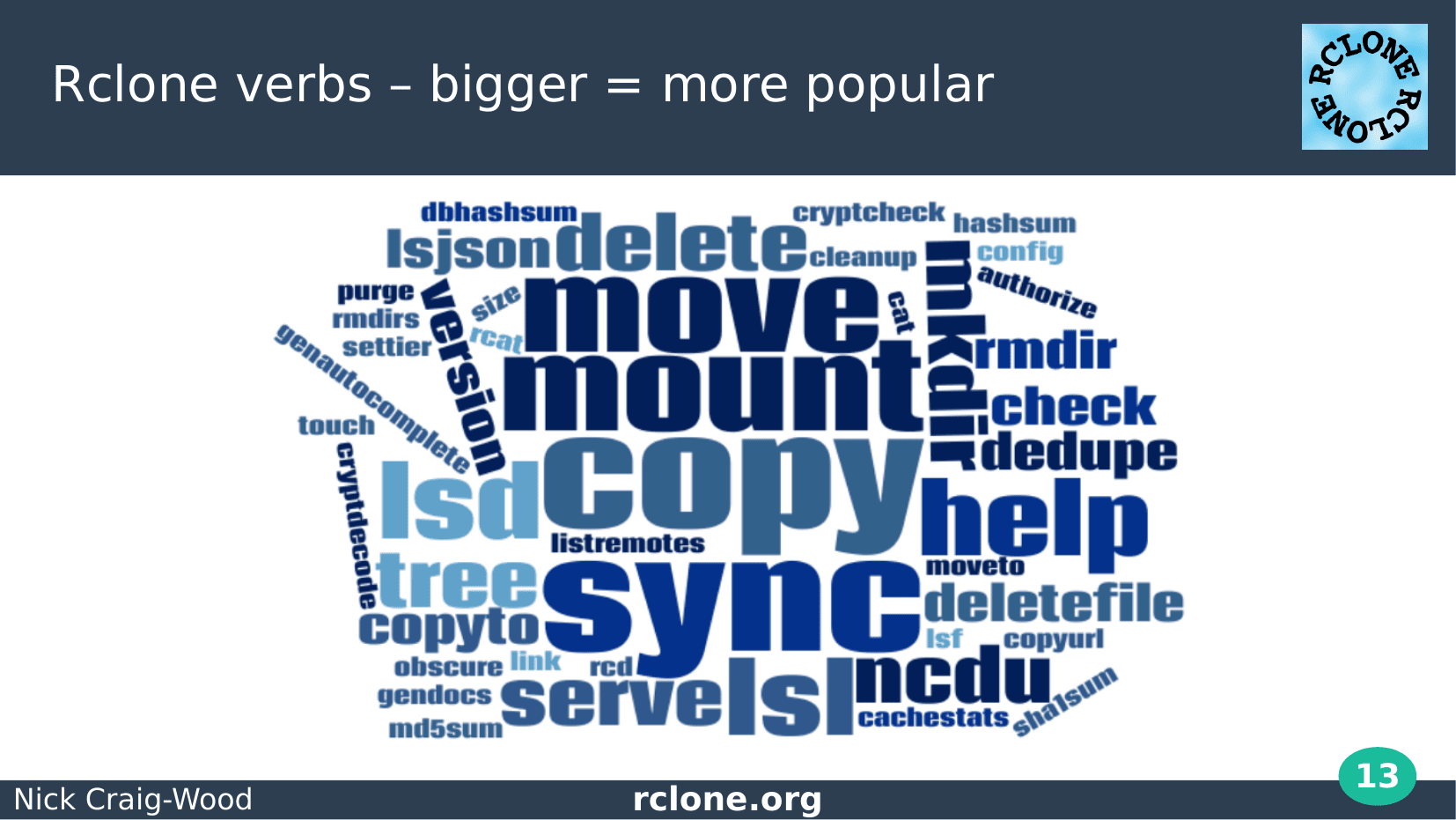
I’ll now move on from the history to how it works.
There are a number different functionalities of rclone. Each of these is implemented as a sub command otherwise known as a verb of the main program.
You write the verbs after the command so “rclone config” or “rclone sync”. More parameters can come after the verb.
For data transfer the main 3 verbs are sync, copy and move.

The first command you run after installing rclone is “rclone config”.
This starts up the old school config wizard.
I think I first saw this style of config wizard in perl when configuring CPAN.
It isn’t the prettiest in the world but it gets the job done!
When it needs to do oauth it opens up your browser for you and redirects back to a local webserver to receive the results.

The next thing you are likely to want to do is copy some files.
Here is a quick demo of some files being copied using “rclone copy” and “rclone ls” to list the files.
Always start with “rclone copy” - don’t use “rclone sync” as that can delete files in the destination.

This shows the use of rclone sync.
Rclone sync differs from copy in that it makes the source and destination identical.
This means that it copies files to the destination and deletes any files in the destination which should be there.
Always try with –dry-run first!
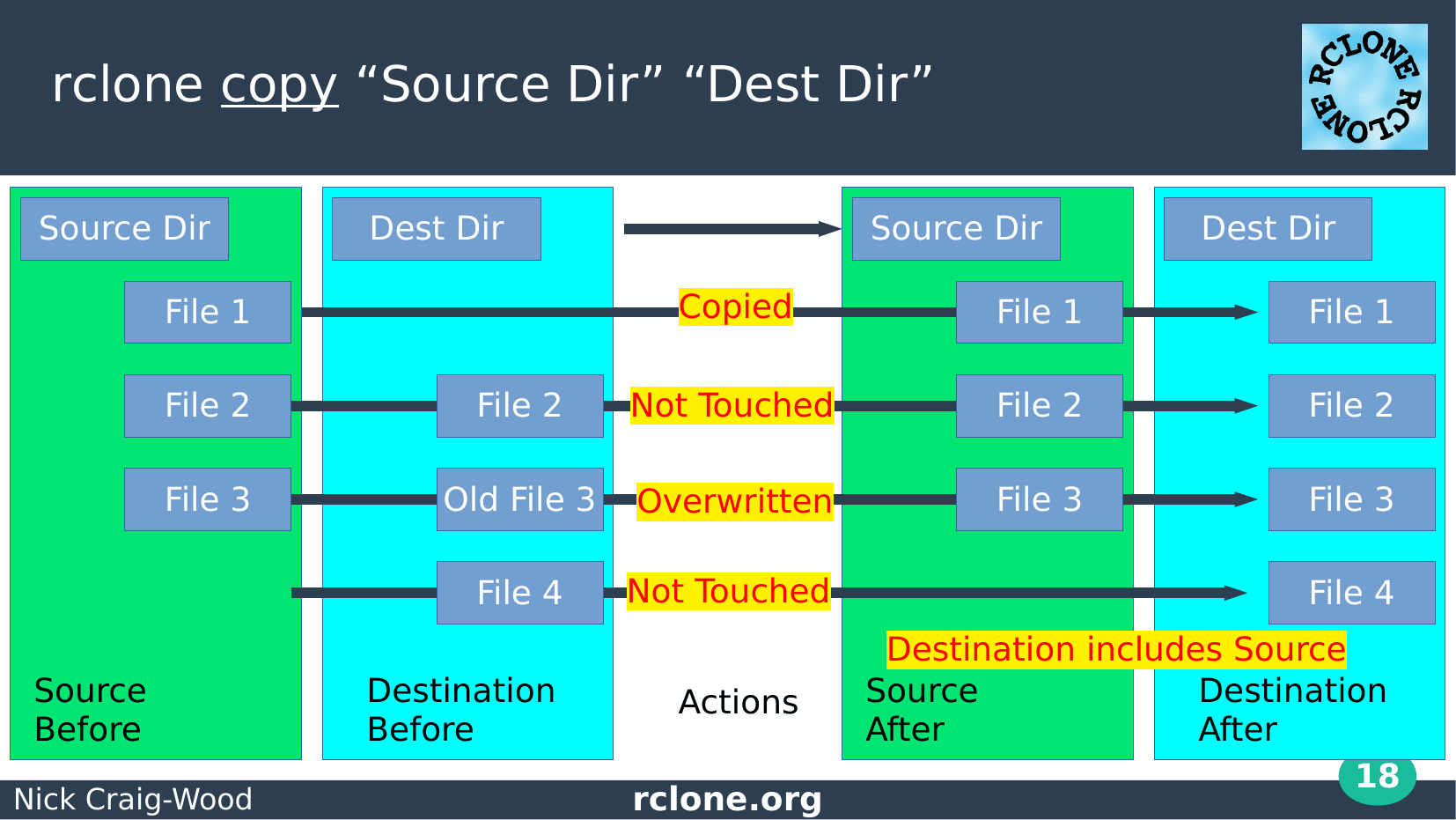
Here is rclone copy in diagram format.
On the left are the source and destination before the command and on the right after the command.
You can see that it can copy a file, ignore an unchanged file, overwrite a stale file and that it doesn’t touch files which exist in the destination already but aren’t in the source.
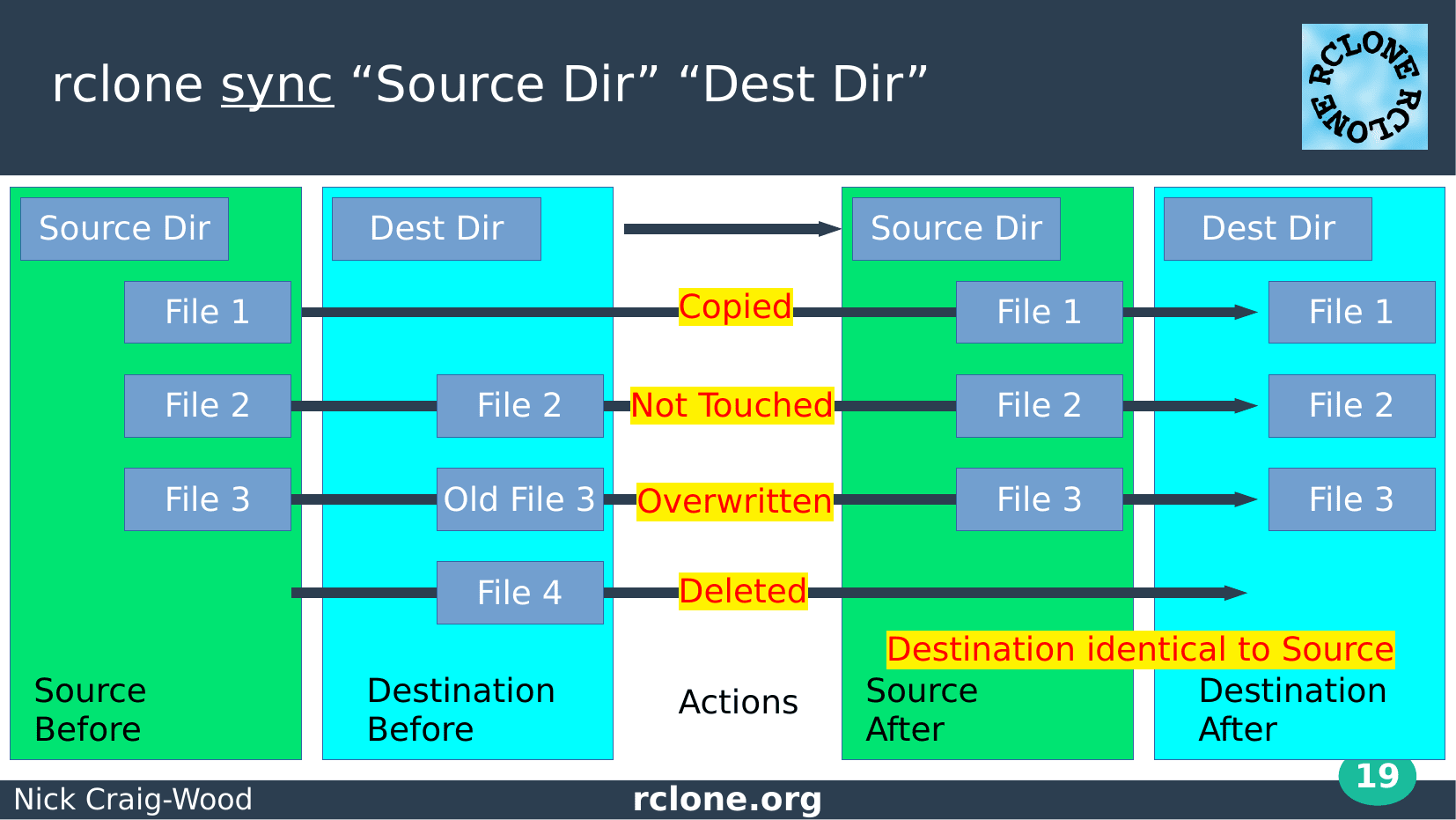
Whereas rclone sync’s job is to get the source and destination identical
You can see that it can copy a file, ignore an unchanged file, overwrite a stale file and that it deletes files which exist in the destination already but aren’t in the source.
Rclone sync, copy and move are all implemented by the same routine as most of the code is identical between them.

Rclone mount is one of my favourite features. Mount any backend supported by rclone as a FUSE mount.
This works on linux, mac and Windows.
Rclone supports seeking on the files too so you can play video quite well from your cloud storage system and I know that lots of rclone users do exactly this.
However if you want to open a file for both read and write or seek while writing then rclone will need to download the file and work on a cached copy. This is part of the VFS layer in rclone which adapts rclone objects to work more like an actual file system.

Here is another of my favourite features.
It is a blatant rip-off or homage as I prefer to call it of the ncdu tool. If you’ve never used it I recommend you install it right away
It is the best tool for answering the question “Where is all my disk space?”. It lets you explore your local disk using a really easy to use curses interface.
I had the idea of implementing that in rclone and I needed something to do on a plane journey so hence rclone ncdu was born.
It uses the excellent termbox library to implement the text based user interface.
Dive into code

Now let’s dive into a bit of code.
Rclone implements its backends using interfaces which won’t be a suprise. This shows the interface which all rclone backends must fulfil.
Rob Pike tells us: “The bigger the interface, the weaker the abstraction” - this is a big interface :-(
It is broken down into 3 sub parts in the rclone source but I’ve presented the whole interface here as it all as to be implemented for a backend.
You can see the kind of methods you might expect, List, NewObject, Put and Mkdir.
There are also some missing from that list which I’ll cover in a moment, like Copy.

This is the interface a cloud storage object must fulfil.
Again pretty straight forward. Note the Hash method which you call with one of the types the Hashes method in the Fs object returns.
Open reads the object and Update sets its contents.
You can also read the modification time and set the modification time – something that is very important for rclone syncing.

All the backends support the interfaces in the previous two slides. However some backends can do more, and rclone can use that.
For example the Purge interface deletes a directory and everything under it. Some backends can do that and some can’t.
For example, say you were doing a server side move of an object. Some backends can do that immediately with the Move method (for example Google Drive). Some support Copy but not Move (for example S3). Rclone will Copy the object then Delete it. And some don’t support either (eg B2) in which case rclone will download the object and upload it again.

Here is how you might use those optional interfaces – with an type assertion. That is straight forward go code.
However, rclone backends can wrap other backends, for example the encryption backend. The outer backend wants to expose what the inner backend can do so must implement all optional methods. The inner backend may not implement all optional methods so we’ve got a problem.
The traditional solution to this is a sentinel error which we check. Here we call Purge and check the err value against ErrCantPurge.
This works very well, provided you don’t want to know which methods are used in advance. Unfortunately rclone does need to know….

The solution to that is a good old fashioned struct full of function pointers. This is filled in with a bit of reflection so doesn’t take any manual work to keep up to date.
Backends which wrap other backends logical AND their own features with the features of the wrapped backend to make the final Features struct.
To use Purge, say, you just check to see if the pointer is nil. If it isn’t nil that means the method is supported so you can call it.
Those of you who’ve used C++ will realise this is a re-implementation of the vtable or virtual table. Go made the implementation straight forward though.
Testing

Lets go into how rclone is tested.
As you saw earlier rclone supports lots of providers, it has lots of commands, architectures OSes. That all makes it really hard to test.
Anyone think writing mocks for 27 different cloud providers would be much fun for a hobby project? No?
So rclone does lots of integration tests. These give real confidence that rclone works properly and keeps on working. After all cloud providers often change stuff.
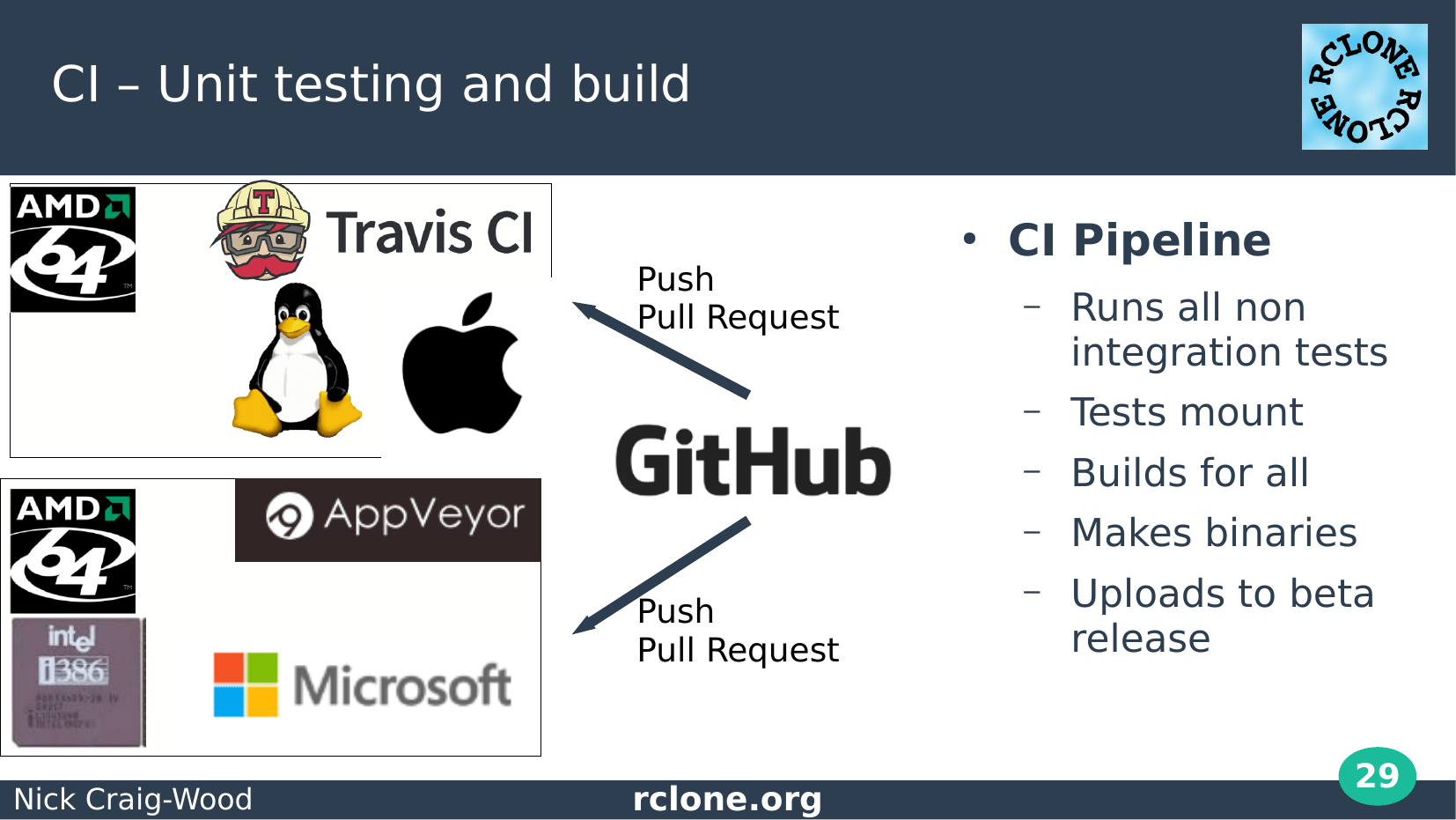
Rclone has a full continuous integration pipeline.
I think we are amazingly lucky as open source programmers to be able to use Github, Travis and Appveyor for free – they are fantastic tools.
The CI tests run all the non integration tests and builds binaries for all the platforms, uploading them for beta release automatically for every branch pushed to the main repository.
You’ll find those at beta.rclone.org

The integration tests run on a separate server.
These run the tests, which are just normal go unit tests with some extra flags against all the backends.
Running these tests costs money and takes a long time so I don’t run them against every pull request, only against the master branch and only once per day.
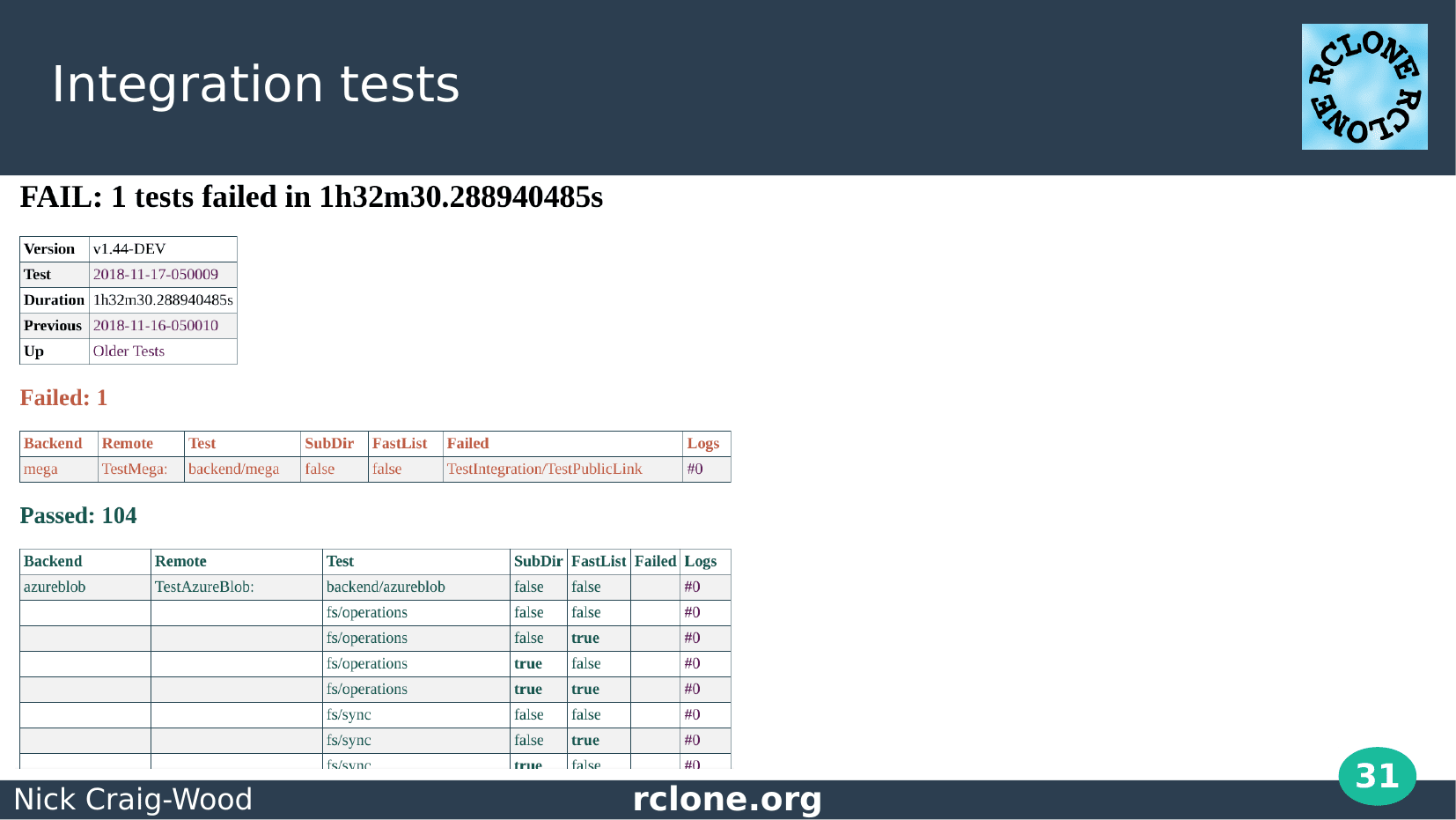
The integration tests produce a report for the developers to look at.
This was a good day with only one failure out of 105 tests.
Often there are lots of failures, usually because of some cloud provider glitch, but sometimes because of a change in the rclone code.
Making a pretty report (well that is pretty by my standards) wasn’t high on my priority list. However I completely messed up one of the releases by misreading the old report, so I made a report which couldn’t be misunderstood.

The integration tests rclone uses are standard go tests. It is easy to add flags to the go tests and rclone adds a “-remote” flag to tell it to run the tests against an actual backend.
Unlike unit tests, integration tests often fail. The internet is a messy place – things go wrong. The test_all framework re-runs the tests that fails to try to get them to pass.
I should probably take the time to open source this framework as it could be useful elsewhere!

In go1.6 the concept of nested tests was introduced.
This made rclone’s life much easier. As you can see it is only a few lines of code to run the integration test suite for a backend. Some backends run the suite more than once with different parameters.
When making a new backend, you can use the integration tests as a guide for what you need to work on next and it makes the process quite enjoyable.
Pre go1.6 code generation was used to make the integration tests which was rather painful so thank you to the Go team for making nested tests.

This is something that not many people know, but can make your life much easier.
You can add flags to tests. You don’t need to do anything special, just define flags with the standard library flag package.
There are some great examples of this in the standard library, for instance using a “-golden” flag to make the tests files.
Rclone uses flags to indicate that tests should run with a real backend, and to help debug those tests.

Rclone is a reasonably large program now, approaching 100 thousand lines of Go code.
However it is built on a fantastic set of libraries some of which I’ll talk about in a moment.
And all of that in turn is built on the go standard library.
Rclone uses the vendor directory to keep that all straight, and we recently switched to “go mod” to manage that.
I don’t think we can drop the vendor directory just yet as rclone needs to support old go versions for the Linux distros that package rclone. Maybe in a year or two.
Tools

I’ll just run through a few of my favourite libraries and tools that rclone uses.
There are loads of other libraries I could have mentioned here so apologies to any authors I’ve missed out.
My first choice is goimports. Install it in your editor and never type an import statement again.
You can see me editing a small file in emacs here and the import statements being automatically added while the code is formatted for you. It works in vim too so I’m told ;-)

Cobra is excellent for organising command line programs with lots of verbs.
I’m sure many of you have used kubectl to control kubernetes or used docker – that is cobra in action.
Cobra comes with a flag library pflag which allows you to create POSIX flags. Flags made by the go flag library are somewhat old school in comparison.
Cobra also creates your bash completion script for all those people like me who use bash, but hate writing bash scripts!

Cobra helps with the documentation. When you write a command cobra makes command help for it and then has a really easy way of turning that into markdown for the website.
A lot of the help on the rclone website was generated this way and it really helps keeping everything consistent.
I then use pandoc to turn the markdown into a man page and one big HTML document for the download.

If you’ve been keeping up with go news you’ll have read the errors proposal for go 2.
The pkg/errors package was one of the motivations for the proposal, so I imagine at some time I’ll be retiring it when go 2 comes along.
You use it to annotate your errors as they bubble up through your code.
This means that rather than receiving a log message with “unexpected EOF” you receive a helpful message which gives you some idea as to what really went wrong.
Conclusion
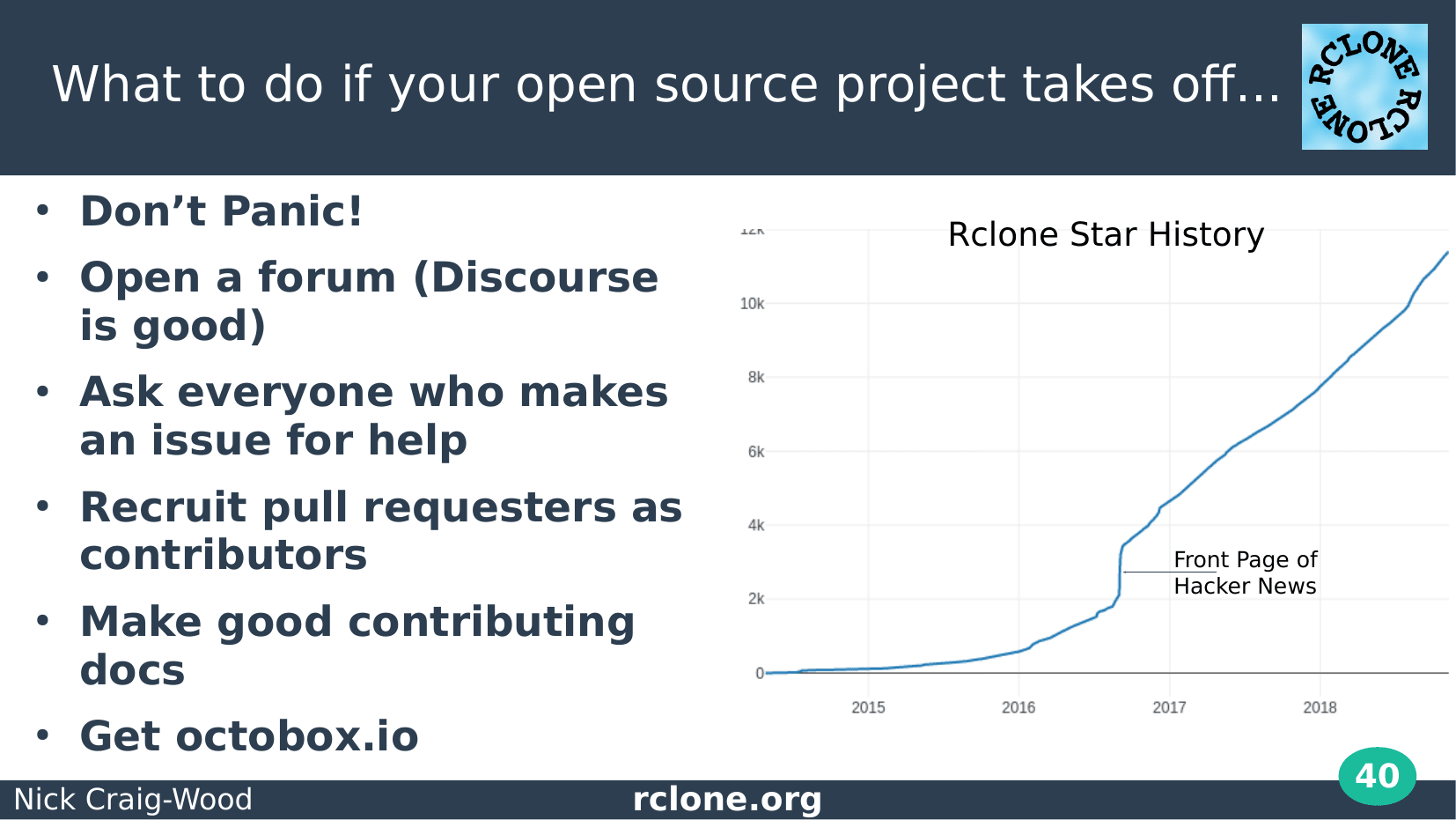
I’m just going to talk briefly about what to do if your open source package takes off.
It is easy to get daunted by 100s of issues most of which are support requests so the first thing to do is open a forum and get the users helping themselves. I use Discourse – it is free and easy to setup and maintain.
Don’t be shy of asking users who make issues for help. You might need to give them a bit of a helping hand, but that is a positive process for both parties.
When you’ve had a few good pull requests from someone, recruit them!
Oh yes, write lots of docs – maybe that should have gone first.
Finally get octobox.io – rather than managing 100s of emails from Github manage them in a nice web interface where you can filter etc.

Thank you all for listening :-)